Загрузка...
Загрузка...
19 июня 2026 г.
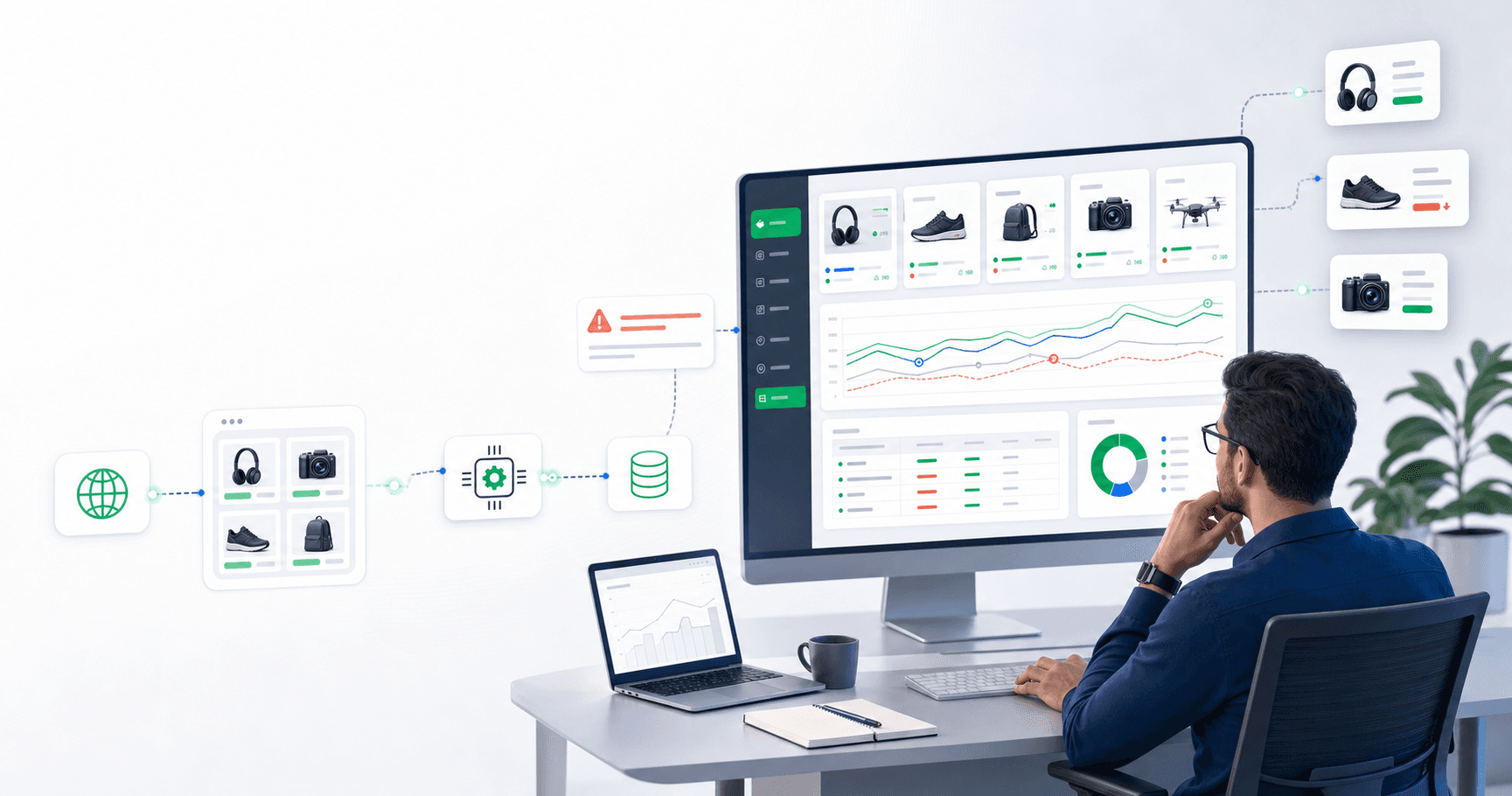
В интернет-магазине цена меняется быстрее, чем ее успевают обсудить на планерке. Один конкурент запустил скидку на ходовой товар, другой убрал доставку из цены, третий поднял стоимость из-за дефицита, маркетплейс поменял выдачу, а менеджер все еще сводит данные в таблице руками. Формально мониторинг есть. На практике решение о цене принимается по устаревшей картине.
Именно поэтому растет спрос на парсер цен конкурентов, системы мониторинга цен и связки с интеграциями API. Бизнесу нужен не просто робот, который раз в день выгружает прайс в Excel. Нужна система, которая понимает, какие товары сравнивать, где цена действительно ниже, где изменилась комплектация, когда надо отправить сигнал менеджеру и когда можно автоматически передать данные в учетную систему.
Ниже разберу, какие запросы сейчас ведут к этой теме, чем парсер отличается от сервиса мониторинга, как запускать проект по шагам, какие ошибки обычно делают внедрение бесполезным и когда кастомная разработка окупается лучше готовой подписки.
Поисковая выдача по теме показывает несколько устойчивых веток спроса: “парсер цен конкурентов”, “мониторинг цен конкурентов”, “парсинг цен маркетплейсов”, “динамическое ценообразование”, “контроль РРЦ”, “анализ цен конкурентов для интернет-магазина”. Это не любопытство ради технологии. За запросом обычно стоит коммерческая задача: не продавать дешевле нужного, не выпадать из рынка и не терять маржу из-за запоздалой реакции.
На стороне владельца бизнеса вопрос звучит проще: “Мы видим цены конкурентов слишком поздно. Как сделать так, чтобы система сама собирала данные и подсказывала, где нужно реагировать?” У маркетолога похожая боль: “Реклама ведет трафик, но товар проигрывает по цене в выдаче”. У руководителя продаж своя: “Менеджеры спорят о скидках, потому что нет единой картины рынка”.
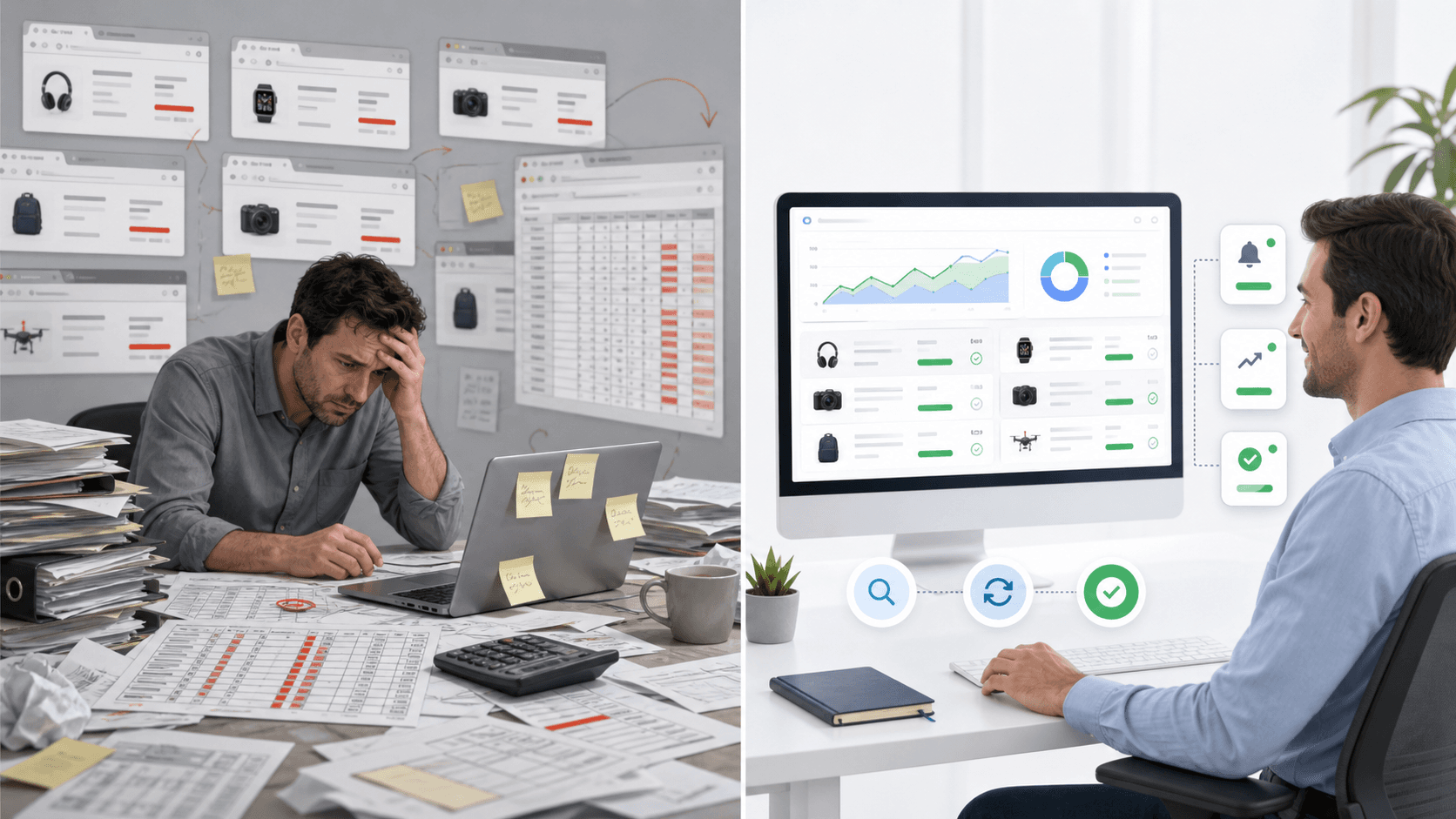
Для этой статьи выбран главный ключ “парсер цен конкурентов”. Стратегия — B, нишевый коммерческий long-tail. Он уже ближе к покупке, чем широкий запрос “парсинг” или “мониторинг цен”: человек ищет не теорию, а инструмент под конкретную задачу. При этом вокруг него удобно собрать дополнительные запросы: “мониторинг цен конкурентов”, “парсинг цен конкурентов”, “парсер товаров и цен”, “анализ цен конкурентов”, “мониторинг цен маркетплейсов”, “автоматизация ценообразования”, “динамическое ценообразование”, “контроль РРЦ”, “парсер цен для интернет-магазина”, “сравнение цен конкурентов”, “интеграция парсера с 1С”, “дашборд мониторинга цен”.
Коммерческая ценность у этих запросов высокая, потому что они связаны с деньгами напрямую. Если компания продает сотни или тысячи SKU, цена ошибки быстро становится заметной: где-то товар продается ниже допустимой маржи, где-то конкурент забирает спрос из-за разницы в несколько процентов, где-то менеджеры тратят часы на сбор данных вместо работы с ассортиментом.
Главная ловушка — думать, что мониторинг цен равен сбору одного числа. На практике цена без контекста часто вводит в заблуждение. У конкурента может быть другая комплектация, временная акция, другой регион доставки, отсутствие товара на складе, минимальная партия, бонусы, рассрочка или платная доставка, которая делает “низкую цену” менее выгодной.
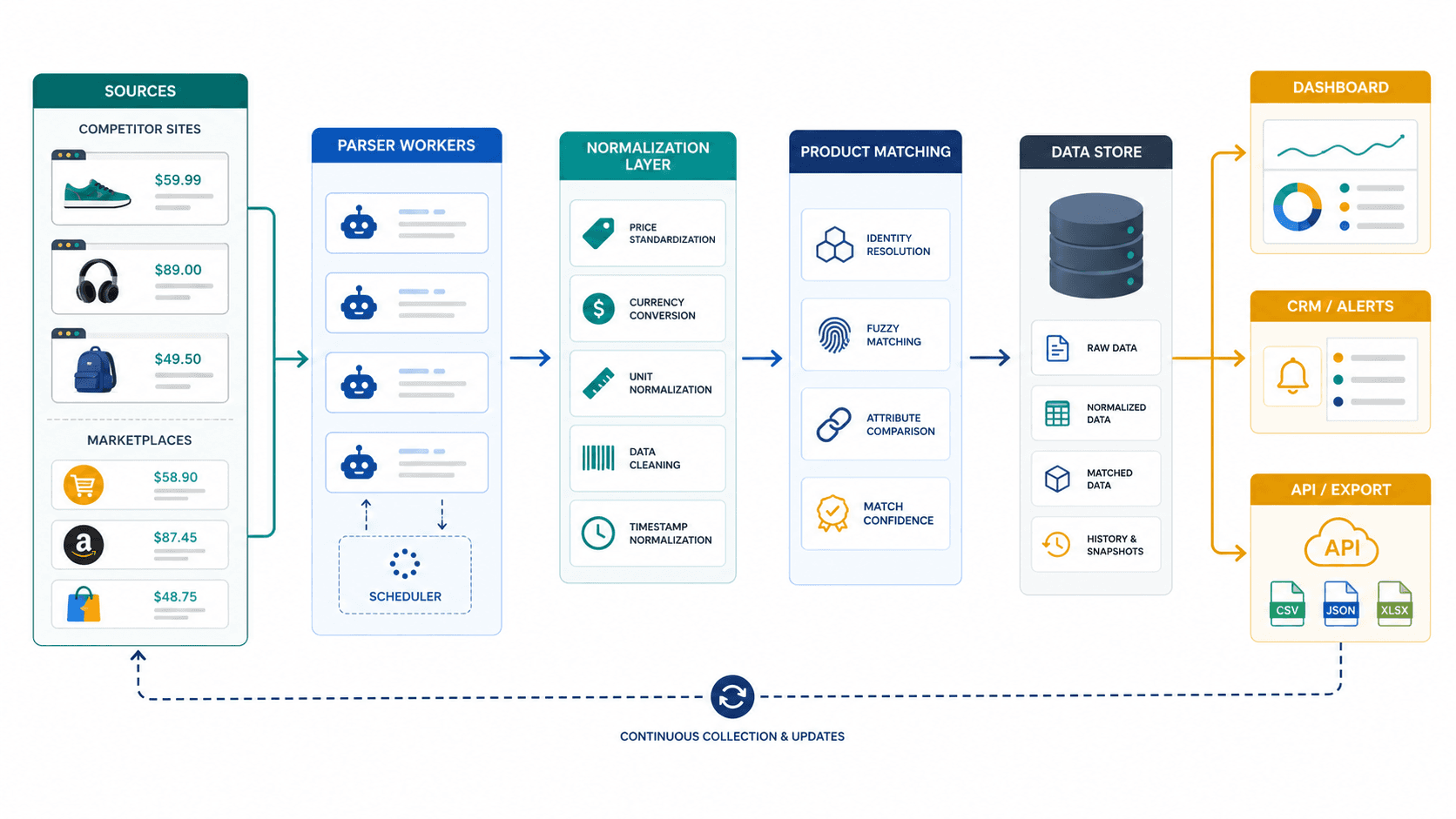
Название товара, артикул, бренд, модель и ключевые характеристики.
Цена, старая цена, скидка, промокод или акция, если они видны на странице.
Наличие, срок доставки, регион, минимальная партия и условия покупки.
Позиция товара в категории или выдаче, если это важно для маркетплейса.
Ссылка на источник и дата последнего успешного обновления.
Признаки совпадения товара: точное совпадение, вероятное совпадение или нужна ручная проверка.
Если собирать только цену, бизнес получает шум. Если собирать цену вместе с контекстом, появляется управленческий сигнал: “мы дороже на 7%, но у нас товар в наличии и доставка быстрее” или “мы дешевле конкурента, хотя могли бы поднять цену без потери позиции”.
Готовый сервис мониторинга цен хорош, когда задача типовая: ограниченный список сайтов, стандартные карточки товаров, обычная выгрузка в таблицу, понятные правила сравнения. Это быстрый старт, особенно если команда пока только проверяет гипотезу и хочет понять, насколько часто цены конкурентов действительно влияют на продажи.
Кастомная разработка становится сильнее, когда мониторинг должен жить внутри процессов: данные надо передавать в 1С, CRM, ERP, внутренний кабинет, BI или отдельное веб-приложение для команды. Еще один сигнал в пользу кастома — сложное сопоставление товаров. Например, у вас разные названия, комплектации, фасовки, аналоги, поставщики и категории, где простого совпадения по названию недостаточно.
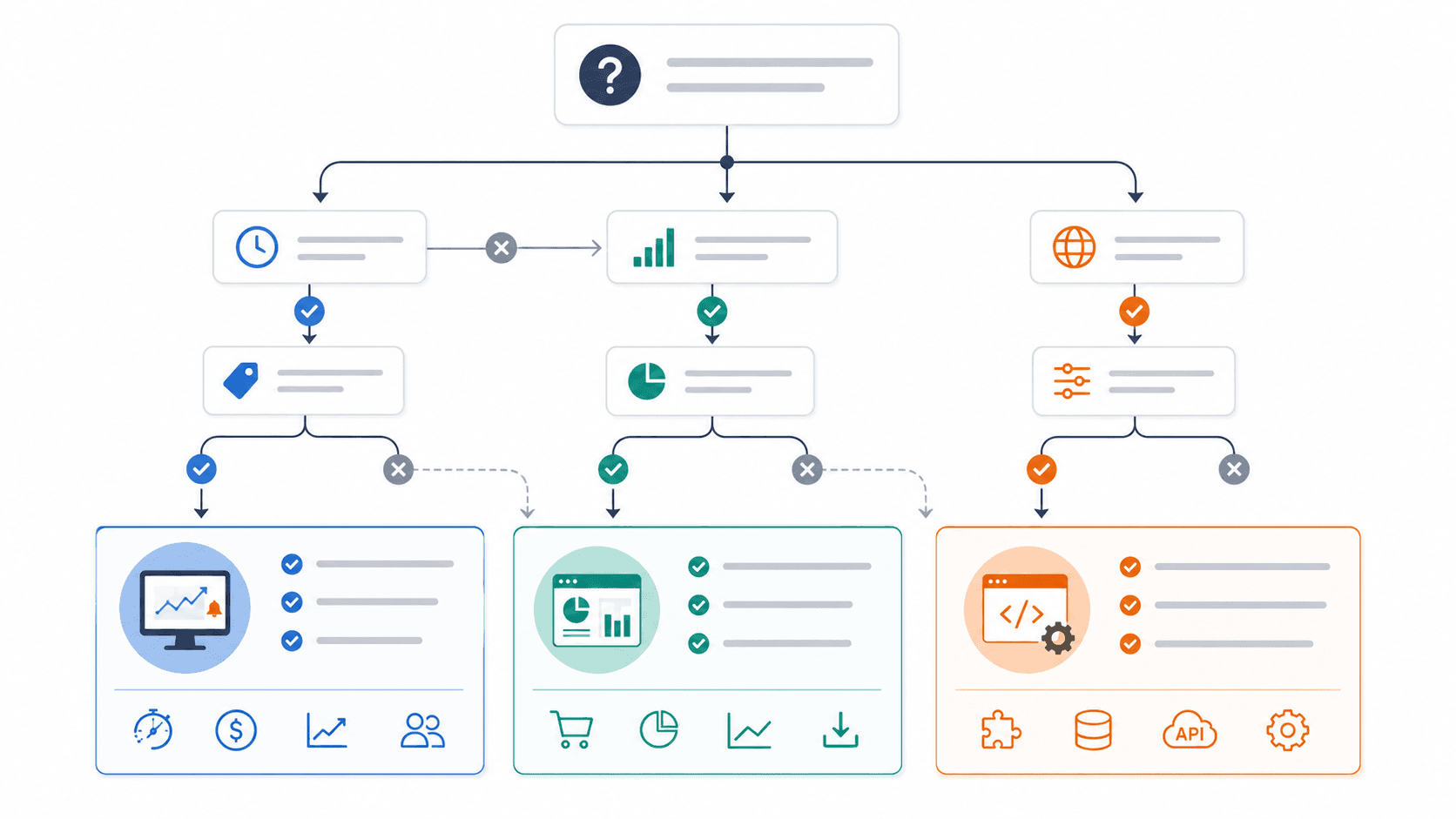
Готовый сервис: быстрее старт, меньше разработки, но меньше контроля над логикой и интеграциями.
Кастомный парсер: дольше проектирование, зато можно учесть специфические источники, правила сопоставления, роли и автоматические действия.
Комбинированный вариант: готовый сервис закрывает типовые источники, а кастомный модуль дополняет его нестандартными данными и интеграциями.
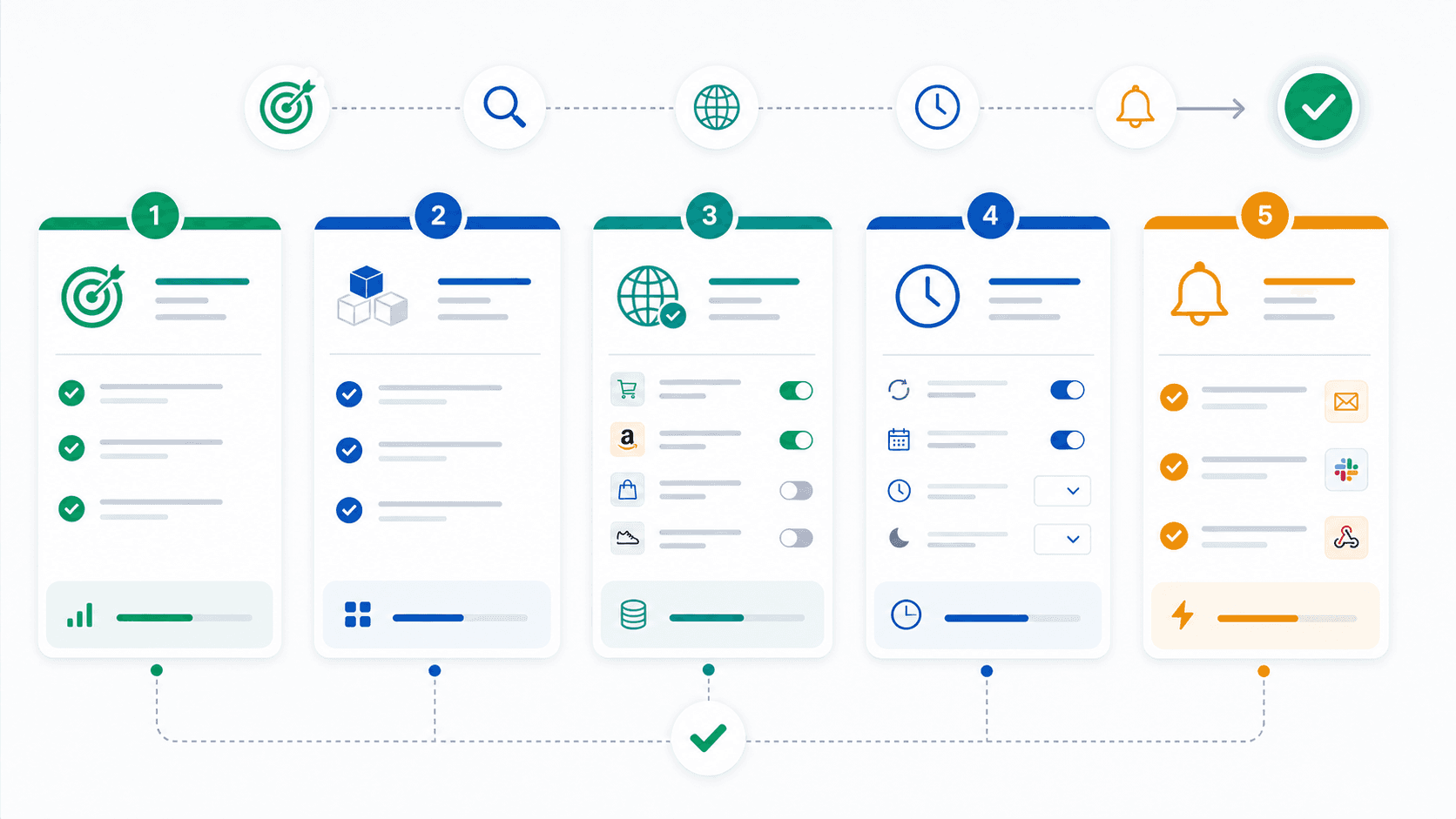
Рабочий проект начинается не с кода, а с решения, какие действия бизнес будет делать на основе данных. Если система просто собирает цены “на всякий случай”, она быстро превращается в еще одну таблицу. Если заранее понятно, кто смотрит сигналы, как часто и какие решения принимает, парсер становится частью управления ассортиментом.
Выберите одну приоритетную категорию или группу SKU, где цена реально влияет на продажи.
Соберите список конкурентов, маркетплейсов и агрегаторов, которые важно отслеживать.
Опишите правила сопоставления товаров: артикул, бренд, модель, характеристики, ручное подтверждение спорных совпадений.
Определите частоту обновления: раз в день, несколько раз в день, по расписанию акций или по критичным позициям чаще.
Настройте хранение истории, чтобы видеть не только текущую цену, но и динамику.
Сделайте дашборд и уведомления: что считать важным изменением, кому отправлять сигнал, какой порог отклонения использовать.
Подключите интеграции: выгрузка в учетную систему, CRM, внутренний кабинет или Data Hub.
Если дальше планируется не только наблюдать, но и менять цены по правилам, мониторинг можно связать с продуктовым сценарием динамического ценообразования. Но автоматическую переоценку лучше запускать после периода наблюдения: сначала убедиться, что данные чистые, совпадения корректные, а бизнес-правила не ломают маржу.
Самая частая ошибка — строить парсер как техническую игрушку: “соберите нам все цены со всех сайтов”. Чем шире старт, тем больше мусора, спорных совпадений и поломанных источников. Лучше начать с узкого контура, где цена данных очевидна, а правила можно быстро проверить на практике.
Собирать слишком много источников до того, как понятны бизнес-решения.
Не хранить историю и видеть только последний снимок цен.
Считать товары совпадающими только по названию, игнорируя модель, фасовку и комплектацию.
Не отделять цену товара от доставки, скидок, региона и наличия.
Не назначить владельца данных: кто проверяет спорные совпадения и обновляет список конкурентов.
Игнорировать ограничения источников, правила площадок и официальные API там, где они доступны.
Не связывать мониторинг с действиями: уведомлениями, задачами, отчетами или изменением цены.
Отдельная тема — инфраструктура данных. Если у компании уже есть несколько источников, полезно не размазывать результаты по разным таблицам, а складывать их в единый контур вроде Data Hub. Тогда цены конкурентов можно сопоставлять с продажами, остатками, рекламными расходами и маржой, а не смотреть на них отдельно от бизнеса.
После запуска важно оценивать не красоту дашборда, а качество управленческого сигнала. Хороший мониторинг цен помогает команде быстрее принимать решения, а не просто создает еще один поток уведомлений. Поэтому на первом месяце полезно договориться о нескольких простых метриках и смотреть их регулярно, без попытки сразу охватить весь рынок.
Доля товаров, по которым найдено надежное совпадение у конкурентов.
Количество спорных совпадений, требующих ручной проверки.
Свежесть данных: сколько времени прошло с последнего успешного обновления по ключевым SKU.
Доля важных ценовых отклонений, по которым команда действительно приняла решение.
Сколько ручных часов ушло из процесса после запуска автоматического сбора.
Какие категории чаще всего требуют реакции: скидка, отсутствие товара, изменение доставки, резкое отличие от рынка.
Если система каждое утро показывает сотни “важных” изменений, но менеджеры открывают только первые десять, это не успех. Значит, нужно менять пороги, группировать сигналы и отделять шум от решений. Иногда лучше показывать меньше карточек, но каждая должна отвечать на вопрос: “Что именно нужно сделать?”
Еще одна полезная метрика — качество источников. Некоторые сайты стабильно отдают данные, другие часто меняют верстку, третьи показывают разные цены в зависимости от региона или авторизации. Если это не учитывать, команда начинает спорить не о цене, а о том, можно ли доверять системе. Поэтому в рабочем парсере должны быть статусы источников, журнал ошибок и понятный способ быстро отключить проблемный канал, не ломая весь мониторинг.
Представим интернет-магазин оборудования с 4 000 SKU. Раз в неделю менеджер выгружает цены трех конкурентов в таблицу. Через два дня данные уже устарели, часть товаров сопоставлена неверно, а руководитель видит только красные и зеленые ячейки без ответа, что делать дальше. В итоге команда либо снижает цены слишком широко, теряя маржу, либо реагирует поздно и отдает спрос конкурентам.
Рабочий вариант выглядит иначе: сначала выбирается 300 ключевых SKU, по ним настраивается ежедневный сбор цен и наличия, спорные совпадения попадают на ручную проверку, история хранится в базе, а дашборд показывает только отклонения, которые требуют внимания. Через несколько недель становится понятно, где нужна автоматизация, где достаточно уведомлений, а где цена вообще не главный фактор продажи.
Есть список приоритетных товаров, а не абстрактное желание мониторить весь рынок.
Понятно, какие конкуренты действительно влияют на продажи.
Описаны правила сопоставления товаров и спорные случаи.
Определены поля кроме цены: наличие, доставка, регион, акция, источник, дата обновления.
Выбрана частота обновления для разных групп товаров.
Понятно, кто принимает решение по сигналам системы.
Запланированы интеграции с CRM, 1С, ERP, BI или внутренней панелью.
Есть критерии качества данных: процент совпадений, ошибки источников, свежесть, полнота.
Если большая часть пунктов уже понятна, можно проектировать систему. Если нет — лучше начать с короткого аудита источников и бизнес-правил. Это дешевле, чем сразу строить сложный парсер и через месяц выяснить, что он собирает данные, по которым никто не принимает решений. В смежных задачах полезна статья про AI-базу знаний для компании: там похожая логика — сначала нужно понять сценарий использования данных, а уже потом подключать технологию.
Автоматический сбор открытых данных требует аккуратности: нужно учитывать условия площадок, нагрузку на источники, доступные официальные API и требования к использованию данных. Для коммерческого проекта лучше сразу проектировать корректную схему сбора, а не строить систему на обходе ограничений.
Зависит от категории. Для медленных B2B-товаров может хватить ежедневного обновления. Для маркетплейсов, акций и ходовых SKU нужна более частая проверка. Обычно частоту делят по группам: критичные товары обновляются чаще, длинный хвост реже.
Можно, но не с первого дня. Сначала стоит накопить историю, проверить качество сопоставления, настроить ограничения по марже и протестировать правила на отдельных категориях. Полностью автоматический репрайсинг без контроля опасен, если данные еще не стабильны.
Не сам сбор страниц, а качество данных: сопоставление одинаковых товаров, обработка разных форматов, проверка наличия, устойчивость к изменениям сайтов и понятные сигналы для команды. Поэтому хороший парсер — это не только код сбора, но и продуктовая логика.
Когда у вас нестандартные источники, сложные товары, нужны интеграции с внутренними системами, своя логика уведомлений, роли пользователей, история изменений и связь с продажами, остатками или рекламой. В этом случае готовый сервис может быть слишком жестким.
GMLB проектирует такие решения как часть цифровой инфраструктуры: парсер цен конкурентов, интеграции с API, CRM и учетными системами, внутренний веб-интерфейс для команды и дашборды для принятия решений. Если хотите понять, нужен ли вам готовый сервис или кастомная система, опишите категорию, источники и текущий процесс через страницу контактов — начнем с короткой диагностики и предложим реалистичную архитектуру без лишнего масштаба.
GMLB проектирует и разрабатывает сайты под конкретную бизнес-задачу: заявки, продажи, доверие, понятную презентацию услуги или запуск нового продукта.
MVP помогает быстро проверить, нужен ли рынку ваш продукт, прежде чем вкладываться в большую разработку, сложную архитектуру и длинный список функций.
Веб-приложение нужно там, где обычного сайта уже мало: пользователи входят в кабинет, работают с данными, создают заявки, управляют процессами или видят персональную аналитику.
AI-агент помогает отвечать клиентам, искать информацию, квалифицировать заявки, готовить черновики решений и снижать ручную нагрузку на команду.
Telegram-бот полезен, когда клиентам удобнее писать в мессенджер, а бизнесу нужно быстро принимать заявки, задавать вопросы, передавать данные менеджеру и не терять обращения.
Интеграции нужны, когда данные живут в разных местах: заявки на сайте, переписки в Telegram, сделки в CRM, отчеты в таблицах, оплаты в платежной системе.